가. Vector Search란?
AI 및 머신 러닝 분야에서 중요한 개념으로, 특히 검색 엔진 및 추천 시스템에서 매우 중요한 역할을 합니다.
- Vector Search의 기본 개념 : Vector Search는 데이터를 수치적 벡터로 표현하고, 이러한 벡터들 사이의 유사성을 계산하여 관련된 정보를 검색하는 기술입니다. 이는 텍스트, 이미지, 오디오 등 다양한 형태의 데이터에 적용될 수 있습니다.
- 벡터 공간 모델(Vector Space Model) : 이 모델은 데이터를 고차원 벡터 공간에 매핑하여, 쿼리와 문서(또는 다른 데이터 형식)간의 유사성을 계산합니다. 각 차원은 특정 특징을 나타냅니다.
- 유사성 측정 방법: 벡터 간 유사성은 주로 코사인 유사도(Cosine Similarity)같은 방법으로 측정됩니다. 이는 벡터 간 각도를 계산하여 유사성을 평가하는 방법입니다.
- 딥러닝과의 연계: 최근에는 딥러닝 모델, 특히 자연어 처리(NLP)에서 사용되는 Transformer 아키텍처 같은 모델을 사용하여 더 정교한 벡터 표현을 생성하는 경우가 많습니다. 이를 통해 더 정확하고 관련성 높은 검색 결과를 얻을 수 있습니다.
- 응용 사례: Vector Search는 검색 엔진, 추천 시스템, 자연어 처리, 이미지 검색, 음성 인식 등 다양한 분야에서 활용됩니다.
나. LLM의 중요한 "Embedding"
- 임베딩의 기본 개념: 임베딩은 단어, 문장, 문단 또는 전체 문서와 같은 텍스트 데이터를 고차원 벡터 공간에 매핑하는 과정입니다. 이 과정을 통해 텍스트 데이터가 수치적 형태로 변환되어, 컴퓨터가 처리할 수 있게 됩니다.
- LLM에서의 임베딩 중요성: 대규모 언어 모델에서 임베딩은 텍스트의 의미를 포착하고, 단어 간의 관계와 문맥을 이해하는 데 중요한 역할을 합니다. 이를 통해 모델은 더 정교한 언어 이해와 생성을 할 수 있습니다.
- 임베딩 방법론: LLM에서 사용되는 다양한 임베딩 기법에는 Word2Vec, GloVe, BERT가 있습니다. 각각이 어떻게 단어의 의미를 벡터 공간에 표현하는지 설명할 수 있습니다.
- Contextual Embeddings: 최신 LLM들은 문맥을 고려한 임베딩을 사용합니다. 이는 동일한 단어가 다른 문맥에서 다른 의미를 가질 수 있음을 반영합니다. BERT, GPT-3 같은 모델들이 이 방식을 사용합니다.
- 임베딩의 응용: 임베딩은 자연어 처리의 다양한 응용 분야에서 중요한 역할을 합니다. 예를 들어, 기계 번역, 감정 분석, 텍스트 요약 등에 활용됩니다.




즉, 임베딩이란 간단히 말해 단어에 숫자를 할당하는 과정입니다. 예를 들어, '고양이'와 '강아지'와 같은 동물을 '1'로, '바나나'와 '사과'와 같은 과일을 '2'로 분류한다고 생각해봅시다. 이 경우 '고양이'는 [1, 1], '강아지'는 [1, 2], '바나나'는 [2, 1], '사과'는 [2, 2]와 같이 표현될 수 있습니다. 이렇게 각 단어는 특정 범주 내에서 숫자로 표현되며, 이는 같은 영역의 단어들을 함께 묶는 역할을 합니다. 더 나아가, '고양이의 습성' 같은 특정 특성은 [1, 1, 1]과 같이 더 세분화된 숫자로 표현될 수 있습니다. 이렇게 잘 구성된 임베딩 데이터는 Vector Search의 기반이 되며, 이를 통해 관련성 높은 정보를 효과적으로 검색할 수 있게 됩니다.
다. Vector Search && Semantic Search
Vector Search와 Semantic Search는 밀접하게 연결되어 있으며, Vector Search는 Semantic Search를 가능하게 하는 핵심 기술 중 하나입니다.
- Semantic Search의 개념
Semantic Search는 단순히 키워드의 일치 여부를 넘어, 사용자의 질의와 관련된 의미와 맥락을 이해하고, 그에 따라 결과를 반환하는 검색 방식입니다. 이는 단어의 의미와 문맥을 고려하 더 관련성 높은 결과를 제공합니다.
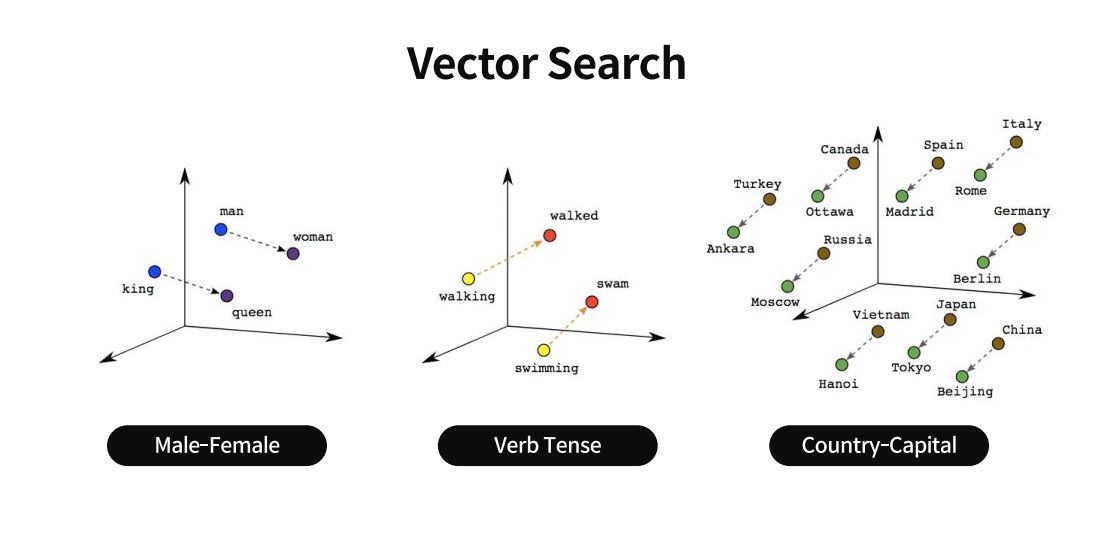

임베딩된 데이터를 활용하여 벡터 간 유사성을 계산하고 관련 정보를 검색하는 Vector Search 기술은 사용자의 문맥을 파악하고 이에 따라 결과를 반환하는 Semantic Search로 발전할 수 있습니다. 이러한 발전은 검색 기술이 단순한 키워드 일치에서 의미와 맥락을 이해하는 더 복잡한 차원으로 나아가는 것을 의미한다.
하지만 이 기술은 만능이 아닙니다. 앞서 언급한 간단한 [1,1,1]과 같은 표현과는 달리, 실제 데이터는 훨씬 더 복잡하게 저장되며, 이를 처리하는 과정에서 속도 문제가 발생할 수 있다. 이러한 속도 문제를 해결하기 위해 Approximate Nearest Neighbor(ANN) 방식이 사용된다. ANN은 모든 벡터를 비교하지 않고 근사값을 찾아 속도를 향상시키는 방법이지만, 이로 인해 검색 성능이 다소 저하될 수 있다.
결국, 이러한 기술적 선택은 프롬프트 엔지니어링의 중요한 부분으로 볼 수 있다. 프로그램을 개발할 때 속도와 정확성 사이의 균형을 어떻게 맞출 것인지 결정하는 것이 중요하다. 사용자의 필요와 응용 프로그램의 목적에 따라 최적의 솔루션을 찾는 것이 프롬프트 엔지니어링의 핵심 과제 중 하나라고 생각한다.
'개발자 > 프롬프트 엔지니어링' 카테고리의 다른 글
| LLM 기반 챗봇 기술 조사 및 구현 접근 방법 (0) | 2024.02.21 |
|---|---|
| 프롬프트 엔지니어링(5) - 좋은 프롬프트 만들기 (0) | 2024.02.19 |
| 프롬프트 엔지니어링(4) - 프롬프트 디자인(구성요소와 예시를 기준으로) (0) | 2024.02.05 |
| 프롬프트 엔지니어링(2) - 개요 (0) | 2024.02.01 |
| 프롬프트 엔지니어링의 기초 (1) Rule-Base AI , Machine Learning (0) | 2024.01.31 |